
Chaque moteur de recherche utilise des robots d’exploration permettant de crawler les pages du web. Le but est de trouver toutes les pages du web puis de les analyser et potentiellement de les indexer sur les résultats de recherche.
Le crawler est appelé robot. Il existe plein de noms de robot pour chaque moteur de recherche comme :
- Googlebot
- Bingbot
- Yandexbot
- DuckDuckbot
- …
La communauté SEO fait souvent référence à Googlebot pour parler des robots d’exploration ou des crawlers. Tout simplement parce que 92 % des recherches sont faites via Google et les 8 % des recherches sont partagées entre tous les autres moteurs. De plus, la majorité des autres moteurs de recherche utilise plus ou moins le même fonctionnement que Google, que ce soit pour les robots, les facteurs de classement, etc.
Il existe une multitude de facteurs pour lesquels le robot trouvera vos pages, nous pouvons nommer quelques exemples comme :
- L’identification d’un lien interne ou externe qui pointait vers cette page
- La page a été demandée au crawl dans la Google Search Console (ce n’est pas parce qu’une page est donnée au crawl qu’elle peut être crawlée ou indexée)
- Identification via Google ADS
- etc.
Après cela, Google va appliquer un arbre de décision gigantesque pour pouvoir prétendre à son indexation.
L’optimisation du crawl est le pilier du référencement technique.
Les algorithmes derrière l’exploration de Googlebot
Une fois que la page a été identifiée par le crawler, Googlebot détermine l’emplacement du site puis le robot va faire ce qu’on appelle le rendering, voir la page telle qu’un internaute la verrait en evergreen (avec la dernière version de Chrome).
Il veut voir la page telle qu’elle apparaît aux internautes et la décortique en plusieurs morceaux.
Lorsque vous voyez une page, vous distinguez un menu, le plein contenu, etc.
Les robots d’indexation procèdent de la même manière pour mieux analyser une page. Il va même plus loin en partageant le site en différents blocs, le plein contenu, les menus, footers, les metas, les balises titres H(n) etc.
Ensuite le robot récupère le code html de la page, le CSS, le JS ou autre fichier externalisé, des URL contenues dans le code html. Puis il envoie toutes ces informations dans un arbre de décision pour l’indexation.
Un crawler est la première interface que le moteur va avoir avec les pages web des sites web.

1. Au départ le bot ne sait pas où se trouve votre site, le robot sait que la page est www.example.com mais il doit retrouver l’endroit physique auquel il est lié. Quelque part sur le web, il doit le faire correspondre à une adresse physique, sinon il ne sait pas y aller. Pour savoir où il se trouve, il va accéder au DNS, domain name service pour connaître la correspondance entre l’adresse et l’endroit physique (serveur, adresse ip, où doit-il demander telle ou telle page web…). Dès qu’il sait où trouver la page, il l’explore.
2. Ensuite il y a l’analyse syntaxique de la page. C’est alors que Google fragmente les différentes parties de la page.
3. En troisième partie il va se demander s’il a déjà vu le contenu. On dit qu’il vérifie si le document est dupliqué. L’analyse de duplication d’un document se fait au moment du crawl.
Chaque fois qu’un document est crawlé il va vérifier si ce contenu est dupliqué. C’est précisément à ce moment-là, c’est-à-dire au crawl, que l’analyse de duplication est effectuée. Selon le nombre de fois où un document est considéré comme dupliqué par rapport à son index, Google décidera par un modèle complexe d’arbitrage (arbre de décision), si le contenu du document est pertinent ou non.
Le brevet de Google décrit très exactement ce qu’il fait :

On regarde quel type de document on a crawlé (html, pdf…).
Puis on regarde ce qu’il se passe, y a-t-il des redirections ?
Google peut alors retrouver l’URL parente, vérifier si le webmaster a indiqué une URL canonique et décider par un arbitrage le contenu original de cette page, qu’il soit du même site ou d’un site externe.
Il prend alors la meilleure des 2 pages (ou des Xn).
Si votre page est dupliquée d’un autre site, alors le contenu original reviendra à l’autre site et aucun de vos X contenus dupliqués ne sera indexé. Si une page de votre site est considéré comme dupliqué avec une autre page de votre propre site, il choisit l’une des deux.
Un des paramètres principaux pour distinguer l’original et la copie pour un site externe est notamment la différence de popularité. En tout cas retenez que l’on peut être pénalisé pour l’indexation de ces pages si le contenu est dupliqué entre votre propre site ou entre des sites externes. Et par pénalisé, j’entends seulement la non indexation de votre ou vos pages concernées mais cela n’impactera pas les autres pages de votre site.
4. Ensuite le moteur passe par d’autres filtres pour examiner la pertinence de votre contenu. Un de ces filtres est le nom de domaine. Google va arbitrer que le rapport coût récompense n’est pas intéressant, ça coûte cher de faire passer les algos pour rien. Ce qui veut dire que pour le nom de domaine il va appliquer plus ou moins de filtres.
Statistiquement les .edu et .gouv sont très peu spammy. En revanche il y a bien plus de chances que ces filtres trouvent quelque chose sur les autres types de domaine comme .biz . Donc dès qu’il voit une extension de domaine statistiquement spammy, il va déployer son arsenal de filtres de spam. Et d’ailleurs, il est possible que les algos de filtres anti-spam détectent des faux positifs (ou faux négatifs).
L’algorithme peut se tromper et décider de ne pas indexer votre page pourtant pertinente. Alors l’idéal est d’utiliser un TLD (extension du nom de domaine) « bon ». Le nom de domaine n’est pas un facteur de ranking en lui-même mais joue tout de même un rôle SEO dans le cas de figure du crawl et des filtres de spam. Il existe encore toutes sortes d’autres critères de filtres à URL, comme les ancres et bien d’autres.
5. Élimination des URL dupliquées, il choisit la meilleure page à indexer et suit potentiellement les recommandations du webmaster s’il a spécifié une URL canonique, bien qu’il sera son unique juge.
6. Autres traitements…
Voici une image décrivant ces propriétés venant du brevet en question :

Vous pouvez vous apercevoir que nous ne pouvons pas parler de toutes les choses différentes que fait Google lors du crawl pour déterminer l’indexation, bien que nous ayons priorisé les plus importantes.
Une fois qu’il a fait toutes ces choses, il va continuer à explorer en détectant tous les liens de la page, qu’ils soient internes ou externes, puis le robot va suivre ces liens pour visiter les autres pages et ainsi visiter le web. Il cherche les autres pages toute la journée, récupère les codes, les envoie à différents algos et recommence. Googlebot explore des milliards de sites web par jour. Oui c’est énorme et ça coûte cher ! Il est obligé de crawler « toutes » les pages au fur et à mesure pour détecter le nouveau potentiel de classement d’une page et ceci afin de trouver les nouvelles pages d’un site et de les indexer.
Il existe des millions de petits agents (robots) qui communiquent et qui se synchronisent entre eux via une base de données.
Crawler c’est difficile
Le web contient plusieurs milliards de sites web dont potentiellement des trilliards de pages. Il est obligé d’y avoir des milliers voire des millions de robots pour parcourir le web et ainsi travailler en parallèle. Il est important de retenir que Google (et les autres moteurs) évite de crawler des pages peu qualitatives. Ils n’ont aucun intérêt à indexer des contenus pauvres ou non utilisables ou même trop difficiles et coûteux comme les Frameworks JS (https://www.search-foresight.com/bonnes-pratiques-seo-frameworks-javascript/). Vous devez faciliter leur travail notamment avec un sitemap et un robots.txt.
Crawl et vitesse
Un bon crawler doit être rapide pour limiter les coûts, mais votre site est-il rapide ? Dispose t-il d’une bonne qualité de code, qualité de serveur… Google a tout intérêt que le web soit rapide. Si une page met une seconde au lieu de dix, le coût est dix fois moins élévé. D’ailleurs depuis longtemps Google fait la promotion d’un web rapide et met à disposition tout un tas de choses pour optimiser la vitesse d’un site comme Google Page Speed Insights. C’est donc ce qui va nous intéresser dans cette deuxième partie : l’impact de la vitesse pour le crawl.
Le quota de crawl c’est la vitesse d’un site
Google a de plus en plus de sites et de pages et doit à un moment arbitrer sur les ressources qu’il va utiliser sur tel ou tel site. C’est là que l’on parle de quota de crawl, Google décide du nombre de fois qu’il va visiter votre site par rapport à plusieurs critères. Il n’existe pas de nombre défini exact ni d’estimation, pour connaître votre budget de crawl par rapport à votre site.
Cependant ce que l’on sait c’est que le quota de crawl, appelé aussi budget de crawl, dépend principalement du temps passé sur un site. On peut plus largement détailler le budget qui vous est attribué en le décomposant par nombre de pages par rapport au poids / taille des pages et par rapport à l’optimisation du code et côté serveur.
Vous pouvez voir sur cette courbe que lorsque le temps passé à télécharger est réduit, le nombre de pages crawlées / téléchargées augmente. Le quota de crawl dépend donc largement du temps passé sur une page. En général le quota de crawl est problématique lorsque vous dépassez les milliers de pages .Mais si votre site est très lent, qu’il y a des URL dupliquées par des URL paramétrées par exemple, qu’il n’y a pas de « domaine préféré », c’est-à-dire qu’il doit crawler chaque version avec et sans www (et bien d’autres facteurs), votre site à 200 pages peut vite se transformer en un crawl de 500 pages pour Google. Si vous ajoutez à ça un site plus lent que les autres en moyenne, votre quota de crawl peut très vite être dépassé. Il est également important d’éviter les codes d’état HTTP négatif.
Les nouvelles pages ne seront pas découvertes et / ou les anciennes pages ne seront plus analysées et donc votre niveau de classement sera quasiment nul.
Astuce : Pour voir les apparitions des Googlebot et estimer votre propre quota de crawl / apparition de Googlebot vous pouvez utiliser des outils comme « Oncrawl » en y téléchargeant vos logs.
Dois-je me préoccuper du crawl ?
Favoriser un bon site bien construit et bien pensé pour le référencement est forcément une bonne chose, surtout que Google adore qu’on lui facilite le travail. De plus si vous souhaitez avoir un site qui génère du trafic SEO vous aurez besoin de contenu et donc de beaucoup de pages. Si vous êtes ici c’est que vous souhaitez être référencé et que vous allez mettre tout en œuvre non ?
Alors faites les choses correctement. Construisez un sitemap, un robot txt et améliorez la vitesse de vos pages qui sera bon pour le budget crawl mais aussi pour l’expérience utilisateur et son facteur de ranking pur (experience de page).
Optimiser son budget de crawl
Pour optimiser votre quota de crawl vous devez :
- Améliorer la vitesse du site.
- Rafraîchir le site : supprimer des pages ou les interdire au crawl comme avec le fichier robots.txt.
- Éviter le plus possible de JS et CSS externalisés.
- Ne montrer que les bonnes pages
Robots.txt
Le robots.txt est toujours pris en compte par les robots d’exploration. Il visite d’abord le robot.txt pour connaître ses directives lors de son exploration. Le robot va ensuite effectuer son crawl en tenant compte de ce que vous lui avez dit de crawler. Il est donc important d’en profiter pour ajouter les pages non crawlables aux pages auxquelles vous avez ajouté des balises no index par exemple. Voici quelques exemples de syntaxe :
User-agent: *
L’étoile correspond au fait que vos directives concernent tous les robots, sinon vous pouvez spécifier comme ceci :
User-agent: Googlebot
Disallow: /dossier/
Disallow permet d’empêcher aux robots l’exploration. Ici en l’occurrence nous empêchons l’accès au répertoire du site qui s’appelle dossier. Ce qui correspondrait à www.createur2site.fr/repertoire/. À ce moment là toute la partie du répertoire ne sera pas crawlée.
Allow: /dossier/images
Allow permet d’indiquer aux user-agents que le répertoire doit être crawlé. Ici nous indiquons que le répertoire images dans le répertoire « dossier » doit être crawlé. Si vous ajoutez le disallow précédent, le robot n’ira pas explorer le dossier sauf la deuxième profondeur concernant uniquement les images de ce répertoire.
Disallow: /*.pdf$
Tout ce qui se termine par .pdf ne sera pas crawlé.
Disallow: /?s=
Permet de bloquer l’indexation de votre moteur de recherche interne
Tips : empêcher l’indexation des navigations à facettes pour les sites e-commerce avec le robots.txt.
Je vous invite vivement à vous rendre sur https://www.google.com/webmasters/tools/robots-testing-tool/ , l’outil de vérification du robots.txt de Google pour être certain de vos indications. Il serait très dangereux de ne pas vérifier ce que vous faites. L’outil vous permet de vérifier les erreurs et de voir ce qu’il va se passer pour telle ou telle URL.
Sitemap et crawl
Le sitemap.xml est une arborescence de votre site. Il est important d’en créer un pour votre site internet, quel que soit le nombre de pages (sauf one page). Une fois créé, n’oubliez pas de l’envoyer à la GSC pour faciliter le crawl et à bien indiquer l’emplacement de votre sitemap dans votre robots.txt . Vous devez ensuite vérifier dans le rapport GSC que les URL sont bien toutes valides.
S’il y a des erreurs vous devez enquêter dessus. Vous retrouverez toutes ces informations dans le rapport couverture :
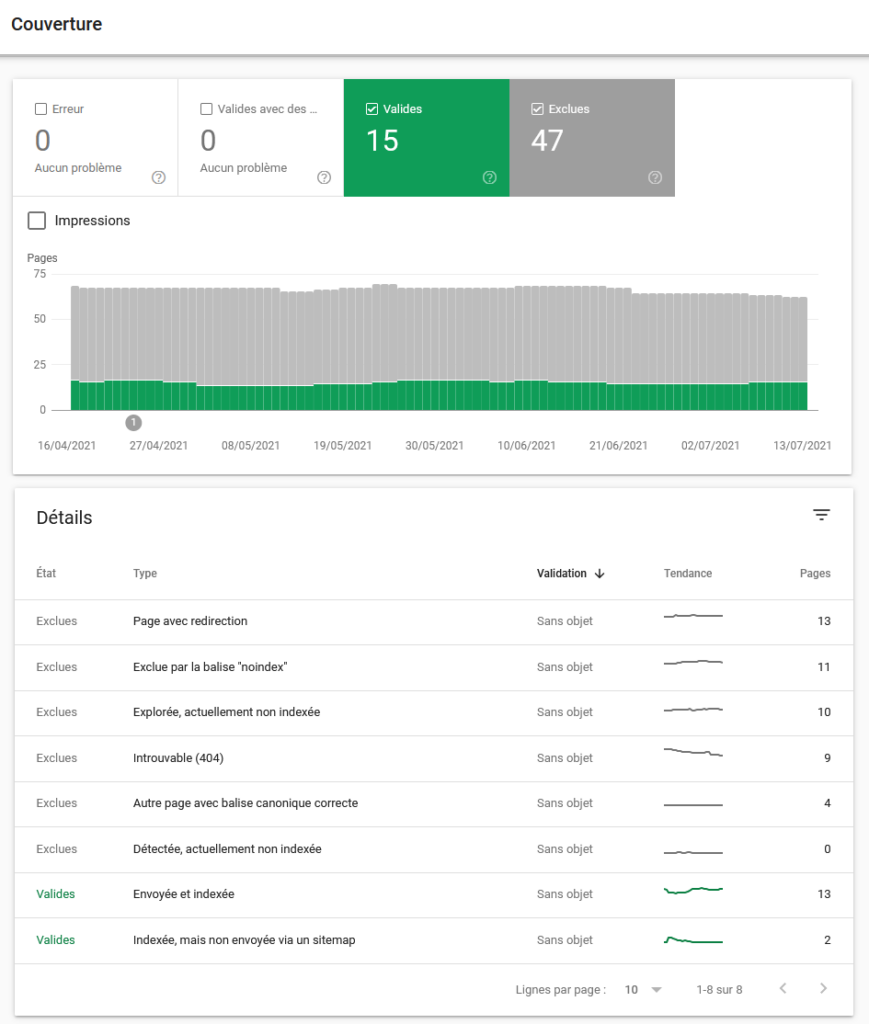
Crawlable ne veut pas dire crawler et veut encore moins dire indexer
L’idéal serait d’avoir : nombre de pages crawlables = nombre de pages crawlées. Mais plein de raisons peuvent empêcher cela comme vu précédemment. L’optimisation du crawl ce n’est pas automatique, alors si elle n’est pas faite il faudra sûrement améliorer votre budget de crawl.
Sachez qu’une page crawlée n’est pas non plus forcément une page indexée, notamment :
- Si le crawl est bloqué par le fichier robots.txt.
- Si la page est orpheline et introuvable sur le site / l’architecture du site. Même si la page est présente sur le sitemap.xml, ne pas l’inclure dans le site est une pratique à bannir.
- Si elle est trop loin dans l’arborescence du site, une page doit être accessible par maximum 4 clics par le robot d’exploration.
- La page est protégée par un mot de passe
- Il y a une redirection
- etc.
Pour récapituler : la page est crawlée, ensuite la page est-elle oui ou non acceptée ? Si oui elle est ajoutée dans l’index. L’idéal évidemment est que le nombre de pages indexables soit bien indexé. Si elle n’est pas crawlée elle ne peut pas être indexée, mais ce n’est pas pour ça qu’elle sera indexée si elle ne passe pas les algos de Google.
Si tout est parfait, le nombre de pages crawlables est égal au nombre de pages crawlées qui est égal au nombre de pages indexables égal au nombres de pages indexées.
Analyser la fréquence de crawl sur votre site
Il existe une multitude de manières différentes pour analyser la fréquence de passage de Googlebot et ainsi déterminer la fréquence de crawl, et donc votre propre quota. Nous allons voir dans ce chapitre plusieurs méthodes différentes.
Googlebot avec Google
Vous pouvez obtenir la date de dernière visite de Googlebot en tapant sur Google (pas votre navigateur) « cache:www.votresite.fr ». Il est possible que vous ne puissiez pas voir le bandeau de Google qui indique la date du passage de Googlebot. Si jamais cela arrive vous pouvez ajouter &strip=1 sur l’URL de votre page tout à la fin.
La date n’est pas très précise sur le cache du moteur de recherche. En général il date de l’avant dernière apparition. Mais pour analyser les sites de ses concurrents il n’y a pas d’autres moyens.
Googlebot avec la Google Search Console
Sinon, pour avoir une date beaucoup plus fiable probablement même exacte, il est impératif de visiter sa Google Search Console. Pour cela vous devez vous rendre dans « inspection de l’URL ».
 Si la page est reconnue mais qu’elle a été modifiée depuis la dernière exploration, vous pouvez demander une nouvelle indexation ou demander une indexation si la page n’a pas été trouvée.
Si la page est reconnue mais qu’elle a été modifiée depuis la dernière exploration, vous pouvez demander une nouvelle indexation ou demander une indexation si la page n’a pas été trouvée.
Si vous n’êtes pas sûr de la dernière date de modification de votre page, il est aussi possible de voir le html lu par Google. Ce qui est intéressant pour vérifier s’il dispose de la bonne version et s’il a bien détecté tout le texte présent sur votre page.
Analyser le crawl d’un site
Les méthodes précédentes vous permettaient d’analyser la dernière fréquence de passage du robot. Il existe trois mois d’historique pour voir les dernières explorations d’une page. Mais faire ça pour toutes ses pages va être très long alors voyons d’autres méthodes !
Analyser le crawl avec la GSC
Pour analyser le crawl de votre site, vous pouvez vous rendre dans GSC → paramètres → « Statistiques sur l’exploration » : OUVRIR LE RAPPORT, ce qui donne :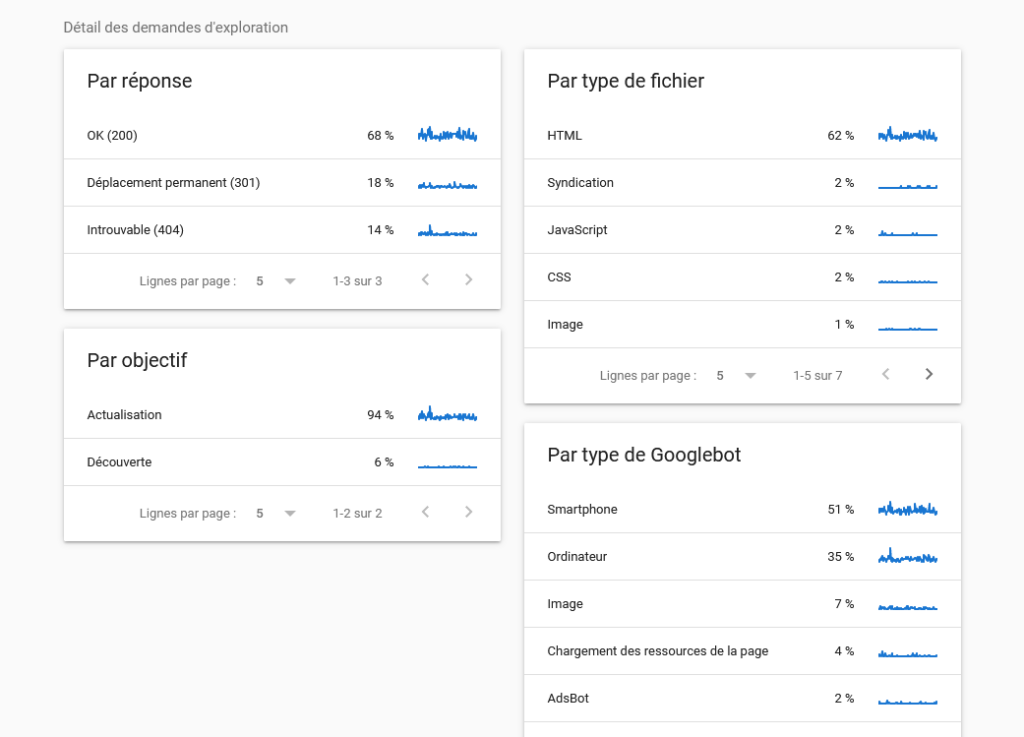
Il y a deux versions principales pour les robots : une version mobile, une version desktop. Vous ne devez donc pas déléguer l’un de des ces deux appareils. Le site est-il compatible mobile ? Le contenu est-il bien identique / similaire entre desktop et mobile que ce soit pour le texte, les balises titles, etc ?. Aujourd’hui Google mobile est majoritaire mais le crawl desktop reste quand même assez présent. Il existe également d’autres robots d’exploration comme les bot d’exploration d’images, vidéos etc.
Faire ce check-up est très important pour vérifier la bonne santé de votre site. Par exemple si par type, le CSS ou le JS prend 60% du temps du crawl, il faudra revoir ces parties-là et faire le ménage.
Analyse du quota de crawl avec des outils SAAS
Bien que Google Search Console soit un outil indispensable, il est tout aussi important d’analyser vos logs d’apparition des Googlebot via des outils complémentaires et plus maniables. Ainsi vous pourrez en savoir beaucoup plus sur ces robots, et pour n’importe quel moteur de recherche en un seul endroit, tout en pouvant appliquer n’importe quel filtre pour prioriser vos actions.
Ainsi je vous conseille quelques outils de crawl comme :
- OnCrawl
- Botify
- ScreamingFrog
- SEOLyzer
- …