
Avant la mise en place des systèmes de recherches d’informations telles que Hummingbird, RankBrain, BERT (pour Google), la recherche était essentiellement de la recherche lexicale.
C’est-à-dire que les moteurs de recherche cherchaient essentiellement des correspondances de chaînes de caractères et leurs fréquences entre la requête et le corpus (analyse N Gram, TF IDF, …)
Aujourd’hui les moteurs de recherches regardent les chaînes de caractères mais aussi le sens et les entités.
Concrètement qu’est ce que ca change ?
Admettons une requête comme : "Quand est-ce qu'il fait nuit ?" et "Quel est l'heure du coucher de soleil ?". Ces phrases ont le même sens et correspondent à la même intention, mais les mots sont totalement différents. C'est là tout l'intérêt de la compréhension sémantique pour les moteurs de recherche, ces deux requêtes doivent correspondre aux mêmes résultats de recherche.
Mais ce n’est pas tout, les moteurs de recherche sémantique se concentrent désormais sur « l’intention » d’un utilisateur et vise à aller au-delà de la signification d’un mot dans le dictionnaire.
Knowledge Graph, Hummingbird, RankBrain, BERT, Neural Matching et recherche sémantique
Lorsque Google a annoncé le Knowledge Graph en 2012, il a commencé à profiler les personnes, les chansons, les lieux, les pays, les nations, les événements (c’est ce qu’on appellent les entité en SEOs).
Hummingbird remplace les mots, et comprend les phrases et non les mots, c’est-à-dire qu’il analyse les requêtes de longues traînes comme véritable composant unique et non comme une suite de mots.
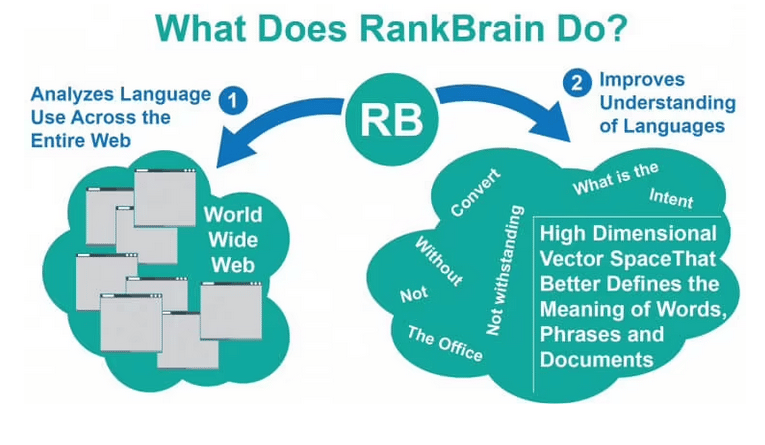
RankBrain mesure si un document peut fournir une satisfaction de recherche réussie et fiable dans une requête.
Avec l'algorithmes Google Hummingbird, Google a commencé à se concentrer sur les "phrases" plutôt que sur les mots-clés et termes.
Neural matching ou correspondance neuronale en français effectuent la correspondance Requête/Document en mesurant ce qu’une requête signifie, tentant de capturer le sens et les concepts.
Mais il y en à pleins d’autres, moins connus, comme Le brevet de Google sur les mots-clés sémantiques (semantic relationship graph) décrivant une méthode pour classer les mots-clés en utilisant un graphe sémantique.
Le graphe sémantique est une représentation graphique qui relie les mots-clés entre eux en fonction de leurs relations sémantiques dans le langage. Les mots-clés sont représentés sous forme de nœuds dans le graphe, reflétant la structure du langage, tandis que les relations sémantiques sont représentées sous forme de liens entre les nœuds.
Le brevet de Google décrit comment utiliser ce graphe sémantique pour classer les mots-clés en fonction de leur pertinence pour une requête de recherche particulière. Grâce à ce graphe sémantique, Google peut déterminer les relations sémantiques entre les mots-clés dans une requête et utiliser ces informations pour affiner les résultats de la recherche grâce à une approche plus précise.
L’objectif de cette approche est de fournir des résultats de recherche plus pertinents en comprenant la signification sous-jacente des mots-clés utilisés dans la requête. Par exemple, si une personne recherche “appartement à louer à Paris”, Google peut utiliser le graphe sémantique pour comprendre que les mots “appartement”, “louer” et “Paris” sont liés par une relation de location immobilière et affiner les résultats en conséquence.
Ce brevet est un exemple de la façon dont le moteur de recherche Google utilise la sémantique pour améliorer les résultats de la recherche et fournir une expérience de recherche plus utile et plus pertinente aux utilisateurs.

Vous pouvez trouver une tonne de brevets du moteur Google sur la sémantique sur le site de SEO By the SEA.
Hummingbird et recherche sémantique
L’algorithme Google Hummingbird permet de détecter et d’inclure les connexions entre les requêtes dans un contexte afin de mieux satisfaire les internautes.
Avec l’algorithme Hummingbird, Google a commencé à se concentrer sur les “phrases” plutôt que sur les mots.
L’ algorithme colibri aide également à réconcilier les synonymes et les requêtes similaires, ainsi, Google a commencé à privilégier les contenus longs avec une meilleure compréhensivité et plus d’informations dans le temps. Parce que le contenu de forme longue a plus de “mots associés” et de “synonymes”, ils ont plus de “requêtes sémantiques” et “d’informations associées” pour l’intention de recherche. Ainsi, avec moins de pages, Google a créé une page de résultats de moteur de recherche plus efficace.
RankBrain mesure selon le contexte de recherche si un document peut fournir une satisfaction de recherche réussie et fiable dans une requête.
BERT et recherche sémantique
BERT (Bidirectional Encoder Representations from Transformers) est un algorithme de Google très important pour la sémantique.
Il permet de mieux comprendre le contenu (mot polysémique par exemple), il permet d’extraire les informations, de détecter les entités et leurs relations et de largement mieux saisir l’intention de recherche d’un internaute.
Neural Matching et recherche sémantique
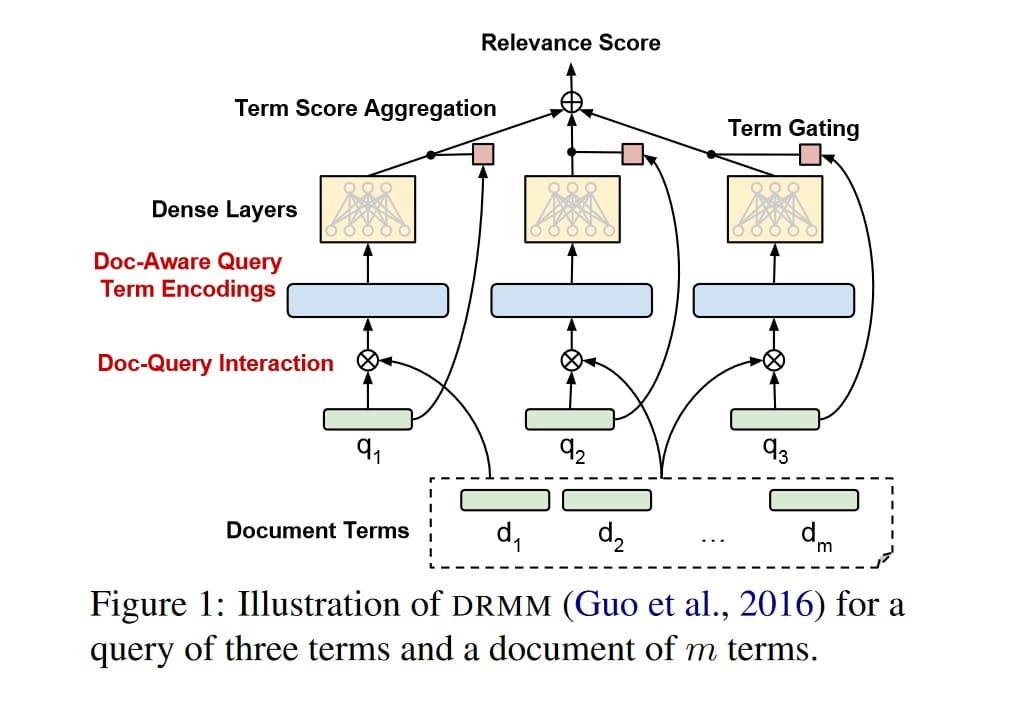
Cette méthode connecte des mots à des concepts pour générer des résultats pertinents.
Cette SEO technique utilise l’extraction ad hoc “classique” telle que TF IDF et le cosinus de salton pour faire concorder des phrases dans des documents et des besoins exprimés dans des recherches. Appuyée par le Deep Relevance Matching Model (DRMM) pour l’extraction ad-hoc, l’algorithme de neural matching permet ainsi de mieux comprendre le sens des requêtes.
https://arxiv.org/pdf/1711.08611.pdf
https://www2.aueb.gr/users/ion/docs/emnlp2018.pdf
Les résultats de recherche sémantique
Les moteurs de recherche tels que Google et Bing enregistrent des milliards de "faits" et des "millions d'entités" dans leur base de connaissances. Tout en enregistrant la connexion de chaque entité entre elles ; Les requêtes de recherche d'entités, les requêtes URL canoniques et les méthodes de réécriture de requêtes permettent de fournir les informations aux utilisateurs et clients dans le format le plus complet.
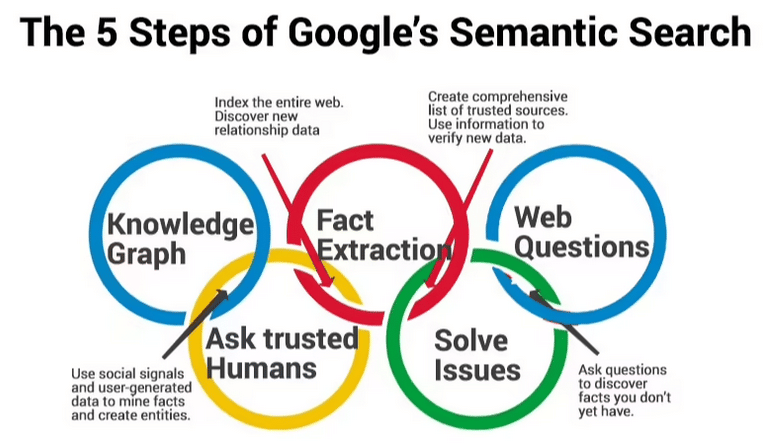
Voici un petit résumé en infographie d’étape possible de la recherche sémantique :
Résultats de recherche dynamiques à plusieurs intentions
Les résultats de recherche dynamiques sont le fruit de la recherche sémantique.
Si un utilisateur recherche une requête avec une intention locale, alors la SERP inclura un panneau Google Maps et des fiches Google Business Profile.
Plus intéressant encore, si un utilisateur recherche des “t-shirts” alors un moteur de recherche sémantique affichera des résultats de recherche sémantique, c’est à dire des résultats connexes à la requête par pertinence. Ce qui donnera alors des résultats liés aux t-shirts mais aussi à des intentions sémantiques la plus probable par rapport à la requête comme des polos.

Ce n’est ni plus ni moins que des “bulles sémantiques”, plus largement appelées “bulles de raffinement de requête”.
La recherche sémantique affiche également en fonction des profils d’utilisateurs différents types d’intention de recherche.
Elle peut également s'adapter et aider les utilisateurs s'il y a des fluctuations de demande de recherche spécifique (dernières nouvelles, événements, …).
Que ce soit Google ou Bing, vous pouvez également obtenir des barres latérales qui permettent d'affiner le "contexte de votre recherche".
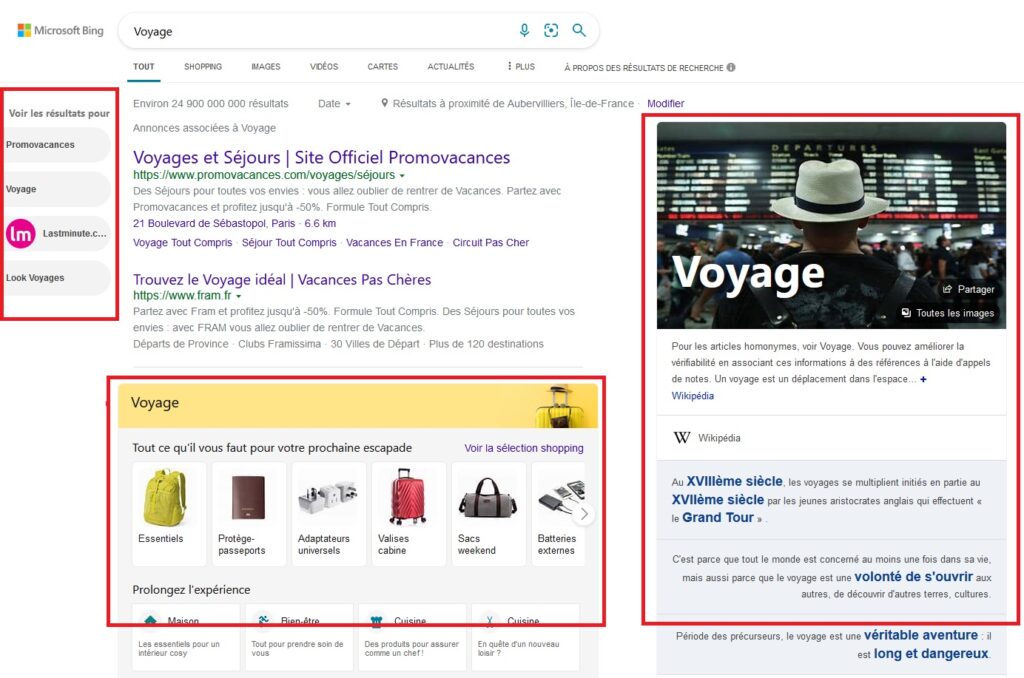
Le contenu dynamique du SERP et la barre latérale d’affinement du contexte de recherche montrent que les moteurs de recherche regroupent le contenu sur le Web en fonction de leur contexte.
Ainsi, la création de différents secteurs verticaux pour différents contextes au sein des SERP permettent aux moteurs de recherche d’afficher un contenu plus configuré pour les utilisateurs en fonction de leurs intentions et comportements de recherche.
Effectivement, au lieu de choisir “l’intention de recherche dominante” et “la source la plus dominante pour un sujet spécifique”, diversifier la SERP avec différents contextes peut aider les moteurs de recherche à proposer plus de contenu.
Un récent brevet, sortit le 4 Janvier 2022 (US-11,216,503) montre que Google peut ne pas trier les résultats en fonction de la qualité des documents de correspondance pour les termes de la requête mais qu’il regroupe les sujets et les relations entre les entités dans le cadre de sa décision sur ce qu’il faut inclure dans les SERP.
Résultats de recherche liées aux entités du Knowledge Graph
Ce qui est aussi impressionnant et très important à savoir pour un référenceur est le lien entre les entités du Knowledge Graph et les résultats de recherche sémantique.
Par exemple, si nous rentrons "chaussure" dans l'API de Google Knowledge Graph, cela nous permet d'obtenir ceci :
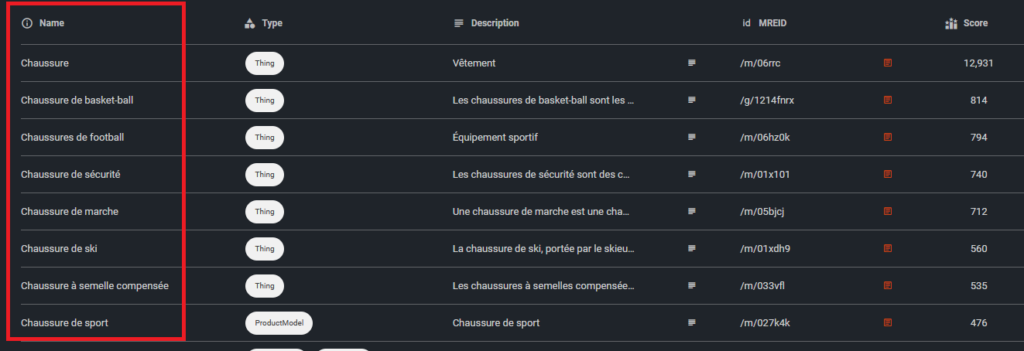
Si vous tapez “chaussures” sur Google et que vous vous rendez dans l’onglet shoppings vous verrez ceci :

C'est important de se rendre compte que les entités du KG ne sont pas forcément que des personnes ou des "entités" mais peuvent finalement être plein de choses pour améliorer la compréhension de Google grâce à la sémantique afin d'alimenter ses résultats de recherche sémantique mais également pour être davantage pertinent et correspondre aux attentes des utilisateurs.
Le référencement sémantique pour la recherche sémantique
Le référencement sémantique vise à faire en sorte qu’un site Web ait un réseau de contenu sémantique en ayant analysé la connexion entre les concepts, les entités, et finalement toutes les autres notions liées à la sémantique comme le sens ou l’intention de recherche.
C’est alors que le référencement sémantique traite de tous les aspects d’un sujet, au lieu des requêtes, il se concentre sur les concepts, leurs connexions, les sujets, l’intention et les entités.
La première étape étant l’analyse sémantique.
Cependant, rien ne vous empêche tout de même d'apporter une analyse basique grâce à TF-IDF pour maximiser vos chances de classement pour vos contenus clients.
Les critères de recherche sémantique pour le référencement sémantique
Explorer, évaluer et comprendre le Web sémantique est beaucoup plus facile que le Web chaotique. Ainsi, les principes de recherche sémantique permettent aux moteurs de recherche d'être plus rentables, plus rapides et axés sur des résultats précis afin d'organiser les informations sur le Web.
La recherche sémantique et le référencement sémantique sont des concepts liés.
Le référencement sémantique est la gestion d’un projet de référencement en étant conscient des fonctionnalités du moteur de recherche sémantique et structuré du moteur de recherche, en sachant quel type de site Web, catégorisation d’URL et de fil d’Ariane et réseau de liens internes vous souhaitez voir pour quel type de réseau de requête . Le format de contenu, le type de contenu, le contexte et la conception de la page sont également organisés dans le contexte du concept de référencement sémantique.

0 commentaires